Los científicos de OpenAI se vieron sorprendidos esta semana al descubrir que una red neuronal entrenada únicamente para predecir el siguiente caracter en los textos de las reseñas de Amazon había aprendido, por sí sola, también a analizar el sentimiento.
Además, necesitó menos ejemplos que los sistemas supervisados para completar su aprendizaje y, posteriormente, en las pruebas de clasificación del sentimiento realizadas, obtuvo mejores resultados que estos.
El sistema también fue capaz de crear textos con el sentimiento deseado.

Los científicos de OpenAI, organización de investigación en inteligencia artificial (IA) sin ánimo de lucro que cuenta con inversores de la talla de Elon Musk o Peter Thiel, dieron a conocer su hallazgo ayer, 6 de abril de 2017, a través de un tweet con un enlace a una explicación más amplia en su blog.
Sin embargo, para poder entender la relevancia de este hallazgo es necesario entender dos conceptos relacionados con el aprendizaje automático: aprendizaje supervisado y aprendizaje no supervisado.
Aprendizaje automático supervisado y no supervisado
El aprendizaje automático (machine learning o ML, en inglés) es la rama de la inteligencia artificial que se encarga de desarrollar técnicas que permitan a las computadoras “aprender”, es decir, conseguir que puedan responder o reaccionar ante una situación o estímulo de manera completamente autónoma sin necesidad de programar su respuesta o reacción previamente.
El proceso de aprendizaje puede ser supervisado o no supervisado. El primero es el más habitual.
Sin entrar en tipos de algoritmos y otros detalles matemáticos, una de las principales diferencias entre ambos es que en el aprendizaje supervisado se entrena al modelo con un conjunto de datos etiquetados, mientras que en el no supervisado se utiliza un conjunto de datos no etiquetados y posteriormente, se le proporcionan solo algunos ejemplos etiquetados.
Pero.. ¿Qué es esto de datos etiquetados y no etiquetados?
El mejor modo de entenderlo es con un ejemplo: imaginemos que queremos entrenar a un modelo de IA para ser capaz de clasificar cuáles de los correos electrónicos entrantes son spam y cuales no.
Un ejemplo de aprendizaje supervisado sería entrenar al modelo de IA con un corpus de correos electrónicos etiquetados como “spam” o “no spam”.
Al analizar dicho corpus el modelo podría extraer una serie de patrones determinantes a la hora de clasificar un correo como “spam”, como que provenga de una determinada IP, que contenga ciertas palabras, etc. Esto le permitiría, posteriormente, predecir si un correo es spam o no.
En resumen, se proporciona al modelo un conjunto determinado de datos, formado por múltiples ejemplos de datos de entrada y los resultados deseados para cada uno de ellos.
Tras analizar todos estos casos de ejemplo, el modelo de IA debe ser capaz de generalizar, extrapolando lo aprendido a nuevos casos no incluidos en los ejemplos.
El principal inconveniente de este procedimiento de aprendizaje es la necesidad de disponer de datos etiquetados. Reunir grandes volúmenes de datos es relativamente sencillo hoy en día, pero etiquetar todos esos datos, a menudo es una ardua tarea que requiere mucho tiempo y trabajo.
En el aprendizaje no supervisado, en cambio, se entrena al modelo con datos no etiquetados y este debe ser capaz de extraer a partir de ellos una buena representación que le permita, posteriormente, ser capaz de resolver las tareas asignadas utilizando sólo unos pocos ejemplos etiquetados.
Lograr esto es el sueño de todo científico de ML y es precisamente lo que los científicos de OpenAI anunciaron haber logrado.

Procedimiento seguido por los investigadores
El objetivo inicial de la investigación era predecir el siguiente carácter en los textos de las reseñas de Amazon. Para ello, los investigadores utilizaron un sistema de IA con una novedosa arquitectura de red neuronal recurrente (RNN) híbrida con memoria de largo y corto plazo multiplicativa (multiplicative Long Short-Term Memory o mLSTM).
Y, utilizando 4 GPUs Pascal de Nvidia, lo entrenaron con 4.096 unidades extraídas de un corpus de 82 millones de reseñas de Amazon.
El entrenamiento no supervisado era únicamente para predecir el siguiente caracter en un fragmento de texto, por lo que las 4.096 unidades no eran más que un vector de valores de punto flotante (float) que representaba las cadenas leídas por el modelo.
El entrenamiento duró alrededor de un mes, al procesar el modelo unos 12.500 caracteres por segundo.
Después de entrenar la mLSTM, los investigadores transformaron el modelo en un clasificador de sentimientos tomando una combinación lineal de estas unidades y utilizando como pesos de la combinación los aprendidos a partir de los datos supervisados disponibles.
Pero al entrenar el modelo lineal observaron que utilizaba una cifra sorprendentemente baja de las unidades aprendidas. Profundizando un poco más, se dieron cuenta de que en realidad se había desarrollado una “neurona del sentimiento” capaz de predecir el valor del sentimiento con elevada precisión.
En definitiva, sorprendentemente, el modelo adquirió también una cualidad interpretable: el concepto de sentimiento.
“La neurona del sentimiento de nuestro modelo puede clasificar las reseñar como positivas o negativas, incluso a pesar de que el modelo solo ha sido entrenado para predecir el siguiente caracter en el texto”, señalan los científicos en el blog de OpenAI.
Resultados punteros en análisis del sentimiento
El modelo de OpenAI no solo necesitó muchos menos ejemplos etiquetados para completar su aprendizaje que los modelos de investigaciones previas, sino que además, en las pruebas de clasificación del sentimiento realizadas posteriormente, obtuvo mejores resultados que estos.
Los investigadores comprobaron la capacidad de análisis del sentimiento de su sistema con el Stanford Sentiment Treebank, un conjunto de datos de análisis del sentimiento pequeño, pero ampliamente estudiado, y obtuvieron una precisión del 91.8%, superior a la mejor obtenida hasta la fecha por otros sistemas supervisados: 90.2%.
En la siguiente gráfica se puede observar también cómo las dos versiones del modelo de Open AI (líneas verde y azul) necesitaron muchos menos datos etiquetados para aprender que los modelos de otras investigaciones previas.
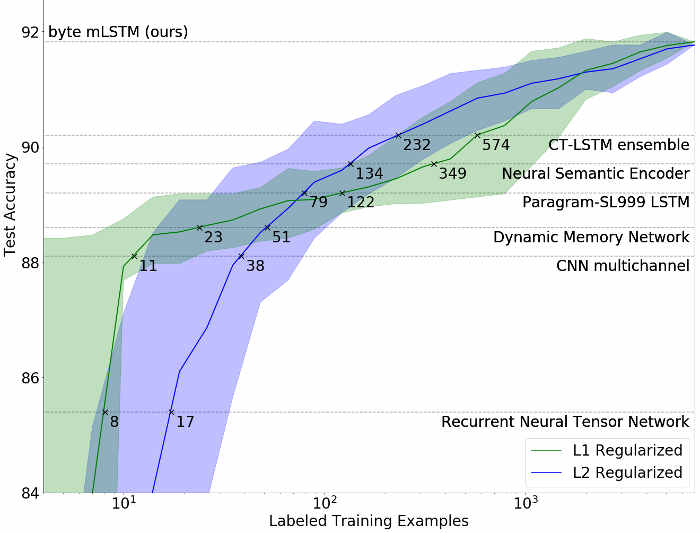
Comparándolos con modelos completamente supervisados como el de las Redes neuronales convolucionales multicanal para la clasificación de oraciones de Yoon Kim (en la gráfica, multichanel CNN) o la investigación puntera de Aprendizaje profundo con gráficos de computación dinámicos publicada recientemente por Moshe Looks, Marcello Herreshoff y DeLesley Hutchins (en la gráfica, CT-LSTM ensemble), ambos entrenados con 6.920 ejemplos etiquetados, el modelo L1 de OpenAI (entrenado previamente con aprendizaje no supervisado a partir de reseñas de Amazon) logró un rendimiento similar al de las CNN multicanal con sólo 11 ejemplos etiquetados y alcanzó el del CT-LSTM ensemble de última generación con tan solo 232 ejemplos.
Implicaciones de este hallazgo para la evolución del aprendizaje automático
Lo que podría ser determinante para la evolución del aprendizaje automático y, consecuentemente, también para la de la inteligencia artificial, es que los investigadores creen que este fenómeno no es específico de su modelo, sino que se trata de una propiedad general de ciertas redes neuronales de gran tamaño entrenadas para predecir el siguiente paso o dimensión en los datos proporcionados como entrada.
En este sentido, estos resultados suponen un paso muy prometedor hacia el desarrollo de un procedimiento de aprendizaje no supervisado general.
Por ejemplo, según los investigadores, entrenar una gran red neuronal para predecir el siguiente fotograma en una gran colección de vídeos podría dar lugar a representaciones no supervisadas para clasificadores de objetos, escenas y acciones.
No obstante, todavía quedan muchos aspectos por resolver.
Por una parte, según los investigadores, los resultados ya no son tan espectaculares cuando se proporcionan al modelo otros conjuntos de datos con textos de mayor longitud.
Por otra, la precisión en la clasificación empeora a medida que los textos proporcionados como entrada se alejan de las características de una reseña.
En este sentido, los investigadores señalan que convendría comprobar si al ampliar el corpus con nuevas muestras de texto el modelo es capaz de elaborar una representación igual de informativa y aplicable a dominios más amplios.
En general, de cara al futuro, los investigadores señalan que “es importante comprender bien las propiedades de los modelos, los regímenes de entrenamiento y los conjuntos de datos que conducen de manera fiable a tan excelentes representaciones”.
Se puede consultar más información en el blog de OpenAI.
Seguir leyendo:
- DNC, el nuevo sistema de IA de Google que aprende por sí solo
- El aprendizaje automático transformará las empresas
- Adobe presenta una asombrosa herramienta de retoque digital con IA
- El robot Flippy completa con éxito su primer día de trabajo en un restaurante
Trackbacks/Pingbacks