Investigadores del MIT CSAIL han presentado los Recursive Language Models (RLMs), una técnica que tiene revolucionada a la comunidad de desarrolladores de IA.
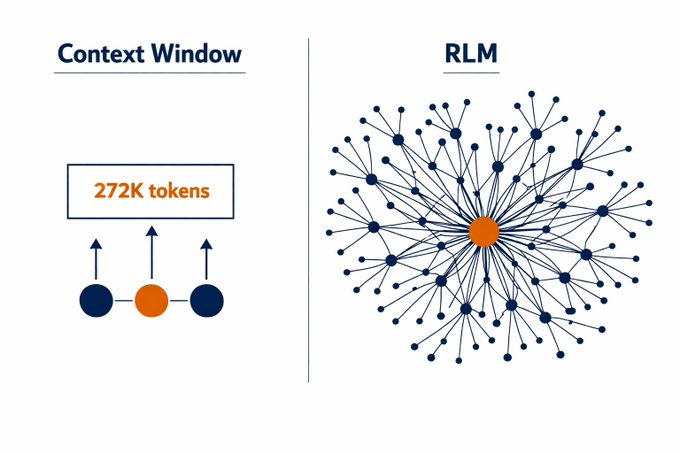
Los RLMs proponen un cambio radical en cómo los modelos de lenguaje procesan grandes volúmenes de información. En lugar de intentar meter millones de tokens directamente en una ventana de contexto gigante, los RLMs convierten el prompt en una variable dentro de un entorno de ejecución (como un REPL de Python). El modelo escribe código para navegar, filtrar y procesarse recursivamente a sí mismo sobre fragmentos relevantes del contenido.
El problema que intentan resolver
La novedad de los Recursive Language Models radica en un cambio de paradigma, en lugar de procesar toda la información de forma lineal, el modelo navega el contenido de forma programática.
Tradicionalmente, cuando se le presenta un documento extenso a un modelo de lenguaje, este debe procesarlo secuencialmente de principio a fin, manteniendo toda la información en su ventana de contexto. Los RLMs cambian este enfoque:
- El contenido se almacena fuera del contexto principal, en un entorno de ejecución (como un cuaderno de Python)
- El modelo escribe código para explorar el contenido: puede buscar, filtrar, extraer secciones específicas
- Se llama recursivamente a sí mismo sobre las partes relevantes, construyendo una comprensión incremental
- Puede verificar y contrastar información consultándose múltiples veces desde diferentes ángulos
Es comparable a la diferencia entre obligar a alguien a memorizar una biblioteca entera de una sola lectura, versus permitirle navegar los estantes, consultar índices, leer capítulos específicos y tomar notas según lo necesite. Esta capacidad de navegación estratégica es lo que permite a los modelos manejar volúmenes de información que serían imposibles de procesar linealmente, incluso con ventanas de contexto de millones de tokens.
Aunque técnicamente un modelo pueda aceptar 2 millones de tokens, su capacidad para utilizar efectivamente esa información se degrada dramáticamente después de cierto umbral. Los modelos empiezan a “olvidar” información, cometen errores de recuperación y su razonamiento se vuelve inconsistente.
RAG (Retrieval-Augmented Generation) surgió como solución: en lugar de meter todo el contenido, busca los fragmentos más relevantes y solo esos se insertan en el prompt. Funciona bien para preguntas puntuales, pero se rompe cuando la respuesta requiere:
- Cruzar información de múltiples secciones de un documento
- Sintetizar cientos de documentos simultáneamente
- Mantener un hilo complejo de razonamiento multi-paso
- Comparar y contrastar evidencia dispersa
Los resultados. Capacidades antes imposibles
Los Recursive Language Models (RLMs) son una técnica que permite a los modelos de lenguaje manejar grandes cantidades de información de forma completamente diferente a lo tradicional. El equipo del MIT evaluó los RLMs en tareas que requieren procesar grandes volúmenes de información simultáneamente. Los resultados demuestran un salto cualitativo en capacidades:
Investigación multi-documento
Esta tarea requería analizar y sintetizar información dispersa en múltiples documentos:
- GPT-5 estándar: 0% (el modelo no pudo completar la tarea debido al volumen de información)
- GPT-5 con RLM: 91% de precisión
Razonamiento con información densa
En tareas que exigen mantener y relacionar múltiples datos complejos:
- Modelo base: 0.04%
- Con RLM: 58%
Estos números no representan mejoras incrementales del 10% o 20%. Muestran la aparición de capacidades completamente nuevas y tareas que eran literalmente imposibles para el modelo estándar se vuelven viables con el enfoque recursivo.
Comportamientos emergentes sin entrenamiento especial
Una de las cosas más sorprendentes de la investigación es que los modelos desarrollaron estrategias sofisticadas por sí mismos, sin ser entrenados específicamente para ello:
- Filtrado inteligente. Utilizaron expresiones regulares para identificar secciones relevantes sin tener que leer todo el contenido
- Descomposición de tareas. Dividieron problemas complejos en subllamadas recursivas más manejables
- Auto-verificación. Desarrollaron mecanismos para contrastar sus propias respuestas consultándose desde diferentes perspectivas
Estas estrategias surgieron naturalmente del hecho de poder programar su propia navegación por el contenido, sin necesidad de ejemplos o instrucciones explícitas sobre cómo hacerlo.
RAG no desaparece mañana
Más allá del hype, necesitamos una visión pragmática de qué significa esto realmente para quienes construyen soluciones de IA en producción. Andrés Desantes, CEO de 1MillionBot ofrece un análisis que contrasta notablemente con el entusiasmo desmedido que ha provocado esta investigación entre la comunidad de desarrolladores.
Según Desantes ” el RAG y sus límites no desaparecen mañana”, los RLMs no son el reemplazo universal del RAG, sino otra herramienta para casos específicos donde el material es enorme y está muy disperso.
El RAG clásico sigue siendo imprescindible como “capa de acceso” al conocimiento: búsqueda rápida, respeto de permisos, versionado, frescura de datos y trazabilidad. La diferencia es que deja de ser un paso único (retrieve → prompt) y pasa a ser una herramienta dentro de un bucle de trabajo.
Mientras el paper original sugiere que RLM puede ser más barato porque “solo lee lo necesario”, la realidad es más compleja. El CEO de 1millionbot señala el riesgo inverso “Si el modelo toma malas decisiones (lo cual es el caso de los modelos actuales), puede recursar de más, repetir trabajo y encarecerse. Por eso la clave práctica es poner límites y buenas reglas: topes de profundidad, presupuestos de tokens, caching de resultados, y checks de verificación.”
Los modelos actuales son todavía inmaduros en este tipo de razonamiento recursivo. Toman decisiones subóptimas, repiten análisis y a veces calculan la respuesta correcta… para luego ignorarla.
Desantes propone una heurística práctica para decidir cuando usar cada técnica:
RAG clásico → Para Q&A rápida y repetitiva con SLAs duros. Será lo más eficiente y estable.
RLM → Para investigación multi-documento, compliance, repositorios enormes o análisis que exige cruzar muchas piezas. Permite planificar, explorar y verificar como lo haría una persona.
La propuesta híbrida
Para Desantes lo mejor es la coexistencia estratégica: “Utilizarlo en paralelo con un sistema de reranking y ponderación según la talla del corpus”.
Este approach reconoce que no hay una solución única. Diferentes casos de uso requieren diferentes arquitecturas:
- treeRAG y RAG predictivo para casos estructurados
- agenticRAG y graphRAG para relaciones complejas
- RLM para navegación profunda multi-documento
- Sistemas híbridos que combinen múltiples técnicas según el contexto
El equipo de 1millionbot ya ha trabajado con estas técnicas avanzadas de RAG, obteniendo “resultados interesantes” aunque conllevan un trabajo importante del equipo de experiencias conversacionales. Los RLMs no eliminan ese trabajo, lo reorientan: de optimizar recuperación única a orquestar navegación multi-paso.
Implicaciones prácticas para equipos de IA
1. No hay que reescribir todo desde cero
Los RLMs funcionan con modelos existentes (GPT-5, Qwen3-Coder) sin modificaciones ni entrenamiento especial. Solo necesitas darles un entorno REPL y acceso recursivo.
2. La gobernanza es crítica
Sin controles adecuados, los costes pueden dispararse:
- Establecer topes de profundidad recursiva
- Implementar presupuestos de tokens por tarea
- Cachear resultados intermedios
- Crear checkpoints de verificación
3. El RAG evoluciona, no muere
Los sistemas RAG existentes no se vuelven obsoletos. Se convierten en componentes dentro de sistemas más complejos donde el modelo puede:
- Recuperar información inicial (RAG)
- Leer y analizar
- Contrastar hallazgos
- Volver a recuperar información complementaria (RAG otra vez)
- Integrar y verificar
4. Nuevos casos de uso posibles
Los RLMs abren puertas que antes estaban cerradas:
- Análisis de bases de código legales completas
- Comprensión de repositorios de millones de líneas
- Síntesis de cientos de papers de investigación
- Procesamiento de años de registros médicos
- Investigación forense en documentación corporativa
A pesar del entusiasmo justificado, es importante mantener los pies en la tierra. Como señala el CEO de 1MillionBot, los modelos actuales son todavía malos en esto comparado con lo que será posible. “Imagina cuando los modelos sean entrenados explícitamente para pensar recursivamente, con mecanismos de verificación integrados y estrategias de navegación optimizadas. Lo que vemos hoy es solo el comienzo”.
Los Recursive Language Models representan un cambio fundamental en cómo pensamos sobre el procesamiento de información por parte de la IA. La pregunta ya no es “¿cómo metemos más tokens en la ventana de contexto?” sino “¿cómo permitimos que la IA navegue inteligentemente por información ilimitada?”.
Pero como bien advierte el CEO de 1MillionBot, esto no significa el fin de las técnicas existentes. Significa su evolución y complementación. Las organizaciones más exitosas serán aquellas que sepan combinar estratégicamente:
- RAG tradicional para eficiencia y SLAs
- RAG avanzado (tree, graph, agentic) para complejidad media
- RLM para exploración profunda multi-documento
- Sistemas híbridos adaptativos que elijan la mejor técnica según el contexto
El futuro no es una técnica que domina todas las demás. Es un ecosistema sofisticado donde cada herramienta se usa en el contexto apropiado, con la gobernanza adecuada y las expectativas correctas.
La revolución de los RLMs es real, pero como toda revolución tecnológica, su verdadero impacto se medirá en cómo la integremos inteligentemente en sistemas de producción que resuelvan problemas reales de negocio.
Referencias:
Recursive Language Models –
Dr. Ismail Šojal🕷️Análisis contribuido por: Andrés Desantes CEO de 1MillionBot