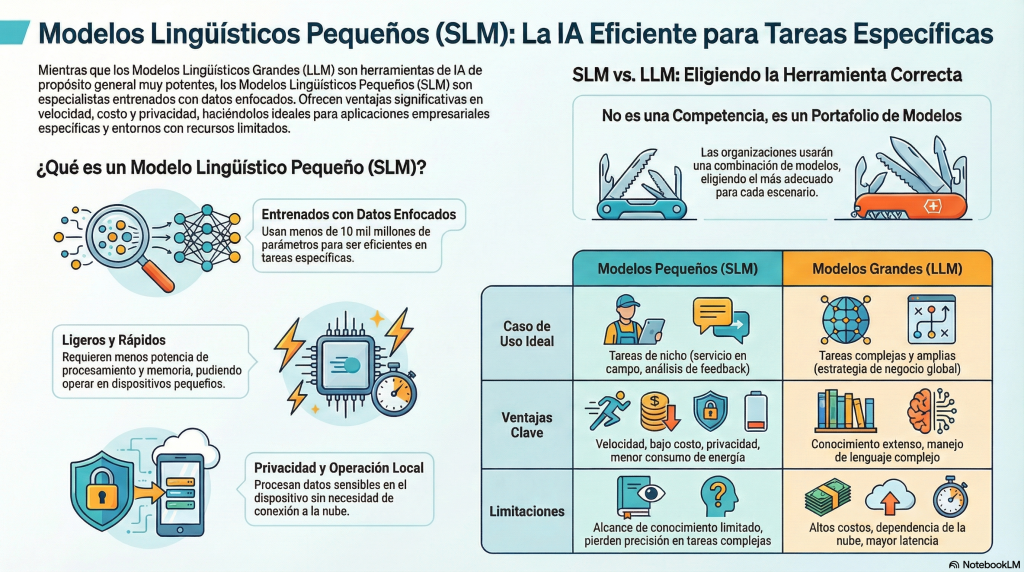
Los Small Language Models (SLM), o modelos de lenguaje pequeños, son sistemas de inteligencia artificial entrenados o afinados con conjuntos de datos más específicos y significativamente más reducidos que los de los modelos de lenguaje grandes (LLM). Mientras que un LLM puede contar con cientos de miles de millones o incluso billones de parámetros, los SLM suelen situarse por debajo de los 10 mil millones de parámetros.
Los SLM están demostrando ser sorprendentemente poderosos, eficientes y, en muchos casos, una opción más inteligente para abordar determinados proyectos de IA, abriendo nuevas posibilidades para empresas y organizaciones. Un estudio reciente del Alan Turing Institute muestra evidencias claras de que estos modelos compactos pueden alcanzar un rendimiento de primer nivel en tareas específicas y bien definidas.
El concepto central es que los LLM pueden resultar “excesivos” para muchas tareas concretas. Aunque son extremadamente capaces, su naturaleza generalista implica mayores costes en términos de recursos computacionales, latencia y presupuesto. Para aplicaciones enfocadas, un SLM suele ser la herramienta más eficiente. Además, permiten implementaciones locales en dispositivos de usuario, donde los datos nunca salen del equipo, reduciendo significativamente los riesgos de privacidad asociados a infraestructuras centralizadas en la nube, habituales en el uso de LLM.
Según el mismo estudio del Alan Turing Institute, un modelo con solo 3 mil millones de parámetros logró un rendimiento de razonamiento competitivo en comparación con modelos de frontera en tareas concretas, y es lo suficientemente pequeño como para ejecutarse localmente en un portátil moderno.
¿Cómo lograron los investigadores alcanzar un rendimiento tan alto en un modelo tan compacto? La clave no está únicamente en los datos, sino en enseñar al modelo un proceso de razonamiento estructurado. Los investigadores observaron que técnicas como la generación aumentada por recuperación (RAG), por sí solas, no eran suficientes. Para mejorar el desempeño, afinaron el modelo utilizando trazas de razonamiento generadas por modelos más grandes. En la práctica, enseñaron al SLM a seguir pasos intermedios: interpretar la información, analizar los documentos recuperados y llegar a conclusiones justificadas, en lugar de limitarse a detectar patrones superficiales.
Además, implementaron una técnica conocida como “budget forcing”, un mecanismo que incentiva al modelo a dedicar más pasos de razonamiento antes de generar una respuesta final. Esto reduce la finalización prematura del proceso y permite abordar problemas más complejos sin necesidad de entrenamiento adicional. Estas técnicas son clave para que los SLM superen parte de sus limitaciones y ofrezcan análisis que, hasta hace poco, se asociaban exclusivamente a modelos mucho más grandes y costosos.
¿LLM versus SLM?
La decisión estratégica no es elegir entre LLM o SLM, sino adoptar un enfoque híbrido. En este modelo, los LLM se reservan para tareas complejas y estratégicas – como el análisis de escenarios macroeconómicos o la planificación a largo plazo-, mientras que múltiples SLM se encargan de tareas operativas específicas de cada unidad de negocio, como el análisis de comentarios de clientes o la monitorización de redes sociales para apoyar el desarrollo de productos.
Es importante aclarar que el hecho de que los SLM alcancen un rendimiento “cercano” al de los LLM no significa que compitan directamente con sistemas como GPT-4, Claude o Gemini en términos generales. Los modelos grandes siguen siendo claramente superiores en comprensión profunda del lenguaje, razonamiento abierto, manejo de contextos amplios y adaptación a tareas nuevas o ambiguas. Lo que demuestran los SLM es que, en tareas específicas y dentro de dominios bien acotados, pueden ofrecer resultados comparables con una fracción del coste, la latencia y la complejidad operativa, convirtiéndose en una alternativa más eficiente -aunque no equivalente- para ciertos casos de uso.
Características principales y funcionalidad de los SLM
- Eficiencia operativa. Su menor tamaño y a su ajuste fino hace que los SLM requieran menos potencia de procesamiento y memoria, lo que los hace más rápidos y energéticamente eficientes.
- Procesamiento local. Pueden ejecutarse en dispositivos pequeños como teléfonos inteligentes, computadoras portátiles o dispositivos del Internet de las cosas (IoT), y a menudo no requieren una conexión a la nube pública para funcionar.
- Especialización. Son muy eficaces en tareas acotadas, como analizar comentarios de clientes, generar descripciones de productos o manejar terminología técnica de una industria especializada,.
Beneficios
- Privacidad de datos: Al ejecutarse de forma local, la información sensible nunca sale del dispositivo, algo crítico en sectores como salud o finanzas.
- Reducción de costes: más económicos en escenarios de alto volumen de tareas sencillas, con costes de inferencia muy inferiores a los de las APIs de modelos de frontera.
- Disponibilidad: ideales para entornos donde el acceso a internet es limitado, como en el caso de ingenieros de campo que necesitan consultar manuales técnicos en zonas remotas,.
Limitaciones y desafíos
Los SLM no son una solución mágica. A pesar de sus ventajas, tienen limitaciones ya que no entienden bien el lenguaje complejo, pierden precisión en tareas muy complejas y su alcance de conocimiento es, por definición, limitado. También tienen los mismos desafíos de gobernanza y seguridad que los LLM y es necesario contar con profesionales que sepan cuáles son los datos correctos para desarrollar una buena estrategia de entrenamiento para el modelo. En resumen:
- Alcance limitado: Tienen un conocimiento más estrecho y no comprenden bien el lenguaje complejo o tareas que requieren una visión macroeconómica o global.
- Precisión en tareas complejas: Pierden exactitud cuando se les pide realizar labores multifacéticas o responder preguntas que varían constantemente (como tasas hipotecarias diarias),.
- Alucinaciones: Al igual que los LLM, los modelos pequeños también pueden inventar información, por lo que requieren políticas de gobernanza y “barandillas” (guardrails) de seguridad.
¿Pensando en implementar un proyecto de IA para tu empresa? En 1MillionBot te ayudamos a elegir, diseñar e implementar la arquitectura adecuada. Contáctanos