Ante el desafío de las “alucinaciones” de la inteligencia artificial (IA), donde las respuestas se desvían en ocasiones hacia lo inesperado, aparece una solución revolucionaria: la generación mejorada por recuperación (RAG, por sus siglas en inglés). Esta innovadora técnica promete no solo corregir fallos, sino también personalizar su conocimiento, abriendo un nuevo capítulo en la interacción con la IA. Descubre cómo RAG está redefiniendo las reglas del juego en el mundo de la inteligencia artificial.
¿Qué son las “alucinaciones” de GPT?
Somos ya muchos los que hemos interactuado alguna vez con un modelo del lenguaje generativo basado en inteligencia artificial, por ejemplo, GPT, y topado con alguna falla. En última instancia se trata de un modelo de machine learning que lo que intenta es predecir el siguiente fragmento (o token) más probable. Cuando empezamos a hacerle preguntas específicas, a plantearle un problema muy concreto o actual, nos damos cuenta de que el modelo puede llegar a decir cosas falsas. Esto es lo que se conoce comúnmente como el problema de las alucinaciones, una situación donde el modelo genera respuestas incorrectas, irrelevantes o inesperadas.
¿Cómo reducir las “alucinaciones” de GPT?
¿Qué opciones tenemos para reducirlas y obtener respuestas más relevantes y útiles? Entre las estrategias propuestas para mitigar este problema (fine- tunning, prompt engineering o regulación de la temperatura), emerge una técnica destacada conocida como Retrieval Augmented Generation ( RAG) o generación mejorada por recuperación en castellano. Esta técnica busca mejorar la generación de respuestas de los modelos de lenguaje mediante la integración de información de fuentes externas, proporcionando un enfoque innovador para personalizar el conocimiento y aumentar la relevancia y utilidad de las respuestas.
A grandes rasgos, la generación mejorada por recuperación es una técnica que consiste en suministrar un conjunto de documentos a partir de los cuales el modelo del lenguaje va a generar la respuesta. De esta forma, el modelo generativo podrá contestar a las preguntas del usuario con respuestas más relevantes, útiles, precisas y pertinentes, guiadas por dicha información recuperada.
La técnica RAG llamó la atención de los desarrolladores de IA generativa tras la publicación de “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” (“Generación aumentada de recuperación para tareas de NLP que realizan un uso intensivo de información”), un artículo de 2020 publicado por Patrick Lewis y un equipo de Facebook AI Research. La propuesta de RAG representó una innovación significativa, ya que los modelos tradicionales de IA se basaban principalmente en conjuntos de datos estáticos y pre-entrenados. La técnica RAG introdujo la idea de que los modelos de IA podrían mejorar significativamente su rendimiento al incorporar información externa, actualizada y específica en sus respuestas.
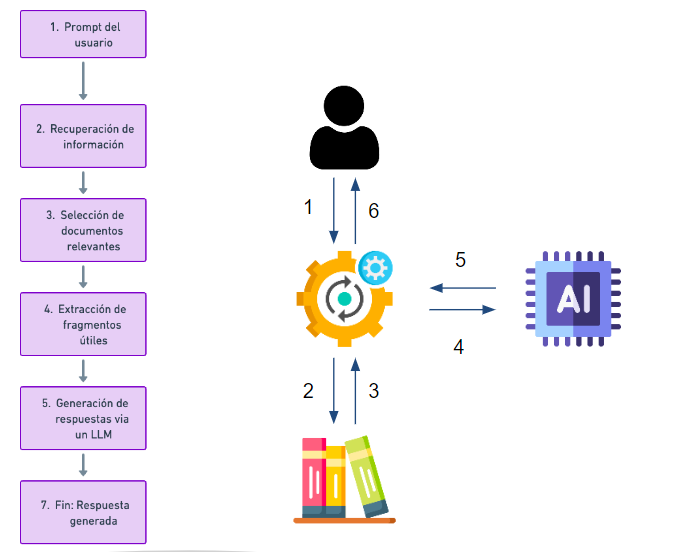
¿Cómo funciona la técnica RAG?
Conectamos nuestro modelo de lenguaje con una base de datos donde se almacenan textos de interés (del tamaño que queramos) y hacemos preguntas sobre información contenida en ella. Así, podemos lanzar una pregunta a nuestro asistente virtual y esta pregunta será procesada por un modelo de búsqueda semántica que se encarga de consultar a una base de datos y recuperar aquellas informaciones que sean relevantes para responder la pregunta.
Este modelo de búsqueda semántica está basado en un tipo de modelos de procesamiento de texto llamado modelos de embedding los cuales tienen la capacidad de transformar un texto en un vector. Las propiedades de estos vectores es que textos que sean similares van a tener vectores similares en el espacio vectorial. Así, lo que tenemos es nuestra base de datos de documentos que se ha convertido en una base de datos vectorial. Cuando un usuario hace una pregunta, se convierte en un vector que se compara con otros en la base de datos para encontrar los más similares y de esta forma crear la respuesta. Un ejemplo de utilización de la técnica RAG es la funcionalidad “Biblioteca” de Millie, la plataforma de chatbots de 1Millionbot. La información que se extrae a partir de la biblioteca se hace con RAG: todos los documentos o URL de la biblioteca están vectorizados; así que, cuando el usuario realiza una consulta, esta se vectoriza, se compara con los vectores de la biblioteca y se extrae la información de mayor similitud.
Además, la funcionalidad “Biblioteca” de esta plataforma, permite a los sistemas de IA acceder y responder utilizando la información contenida en archivos o URL específicos garantizando el control de las respuestas del asistente.
Implementación en empresas y organizaciones
La técnica RAG puede aportar valor real a las compañías. Es aplicable, útil, viable y fácil de implementar. La adaptabilidad de RAG a fuentes de información específicas lo convierte en una herramienta extremadamente valiosa para las organizaciones. Desde manuales de procedimientos internos hasta bases de datos de investigación propietaria, las empresas pueden aprovechar RAG para generar respuestas que no solo son precisas y relevantes, sino también altamente personalizadas a sus necesidades específicas. Esto tiene aplicaciones potenciales en una amplia gama de áreas, incluidas la atención al cliente, la investigación y el desarrollo, y la automatización de procesos internos.
Noticias relacionadas